


eDiscovery expert Tom O’Connor shares 6 essential strategies for tackling big data in the litigation landscape.
Tom O’Connor is a nationally known consultant, speaker, and writer in the field of legal technology. He recently partnered with Nextpoint to publish the 2024 edition of eDiscovery for the Rest of Us, an essential book for legal teams navigating the modern ediscovery landscape. Here, he shares data insights derived from decades of diverse consulting experience, from 90s tobacco litigation to the BP oil spill lawsuit to the ongoing January 6th cases.
Big data – the larger, more complex data sets from multiple and often non-traditional sources – is prevalent in ediscovery. It has overwhelmed the management ability of traditional data processing software and driven the development of advanced computer-based solutions such as TAR and AI.
Let’s look at exactly what big data is and how we can handle it in the ediscovery process.
Part 1: Understanding Big Data
What Makes Data “Big”?
What exactly is “big data”? One company that should know is cloud computing giant Oracle, which says:
“The definition of big data is data that contains greater variety, arriving in increasing volumes and with more velocity. This is also known as the three “Vs.”
And resource center Domo offers this quick and easy calculation:
“The most basic way to tell if data is big data is through how many unique entries the data has. Usually, a big data set will have at least a million rows. A data set might have fewer rows than this and still be considered big, but most have far more.”
The Three V’s of Big Data
- Greater variety
- Increasing volumes
- More velocity
The problem here is not just size. Many programs have limits on how much data they can display or analyze. Large data sets are difficult to upload because of their size, but firms need to analyze the whole data set at once. They can’t just look at portions of the data, so they need a tool that will allow them to inspect everything at once without taking so much time to use that they become impractical.
Data Explosion
The origins of large data sets go back to the 1960s and ‘70s with the establishment of the first data centers and the development of the relational database. By 2005, people began to realize just how much data users generated through Facebook, YouTube, and other online services. Hadoop, an open-source framework created specifically to store and analyze big data sets, was developed that same year.
The development of open-source frameworks was essential for the growth of big data because they make big data easier to work with and cheaper to store. In the years since then, the volume of big data has skyrocketed. With the advent of the Internet of Things (IoT), more objects and devices are connected to the internet, gathering data on customer usage patterns and product performance. The emergence of machine learning has produced still more data, and the COVID-19 pandemic brought a rapid increase in global data creation since 2020, as most of the world population had to work from home and used the internet for both work and entertainment.
What is the Internet of Things?
According to Amazon Web Services, the term Internet of Things (IoT) refers to “the collective network of connected devices and the technology that facilitates communication between devices and the cloud.” It’s all the everyday devices that are connected to the internet, from vacuums to cars to doorbells.
Users, both human and machine, are generating huge amounts of data. So just how much data is there in the world today? Some estimates suggest that the total amount of data on the internet reached 175 zettabytes in 2022. Some studies show that 90% percent of the world’s data was created in the last two years and that every two years, the volume of data across the world doubles in size.
Additionally, there is a substantial amount of replicated data. By the end of this year, 2024, the unique/replicated data ratio is projected to change from 1:9 to 1:10.
How Big is a Zettabyte?
A zettabyte is equal to 1,000 exabytes, or 1 trillion gigabytes.
- 1000 Megabytes = 1 Gigabyte
- 1000 Gigabytes = 1 Terabyte.
- 1000 Terabytes = 1 Petabyte.
- 1000 Petabytes = 1 Exabyte.
- 1000 Exabytes = 1 Zettabyte.
The world’s data volume has increased dramatically in the past twenty years. What led to this explosion in data? First, according to Moore’s Law, digital storage becomes larger, cheaper, and faster with each successive year. Second, with the advent of cloud databases, previous hard limits on storage size became obsolete as internet giants such as Google and Facebook used cloud infrastructures to collect massive amounts of data. Companies around the world soon adopted similar big data tactics. And finally, billions of new users gained internet access across the globe, pushing more and more data accumulation.
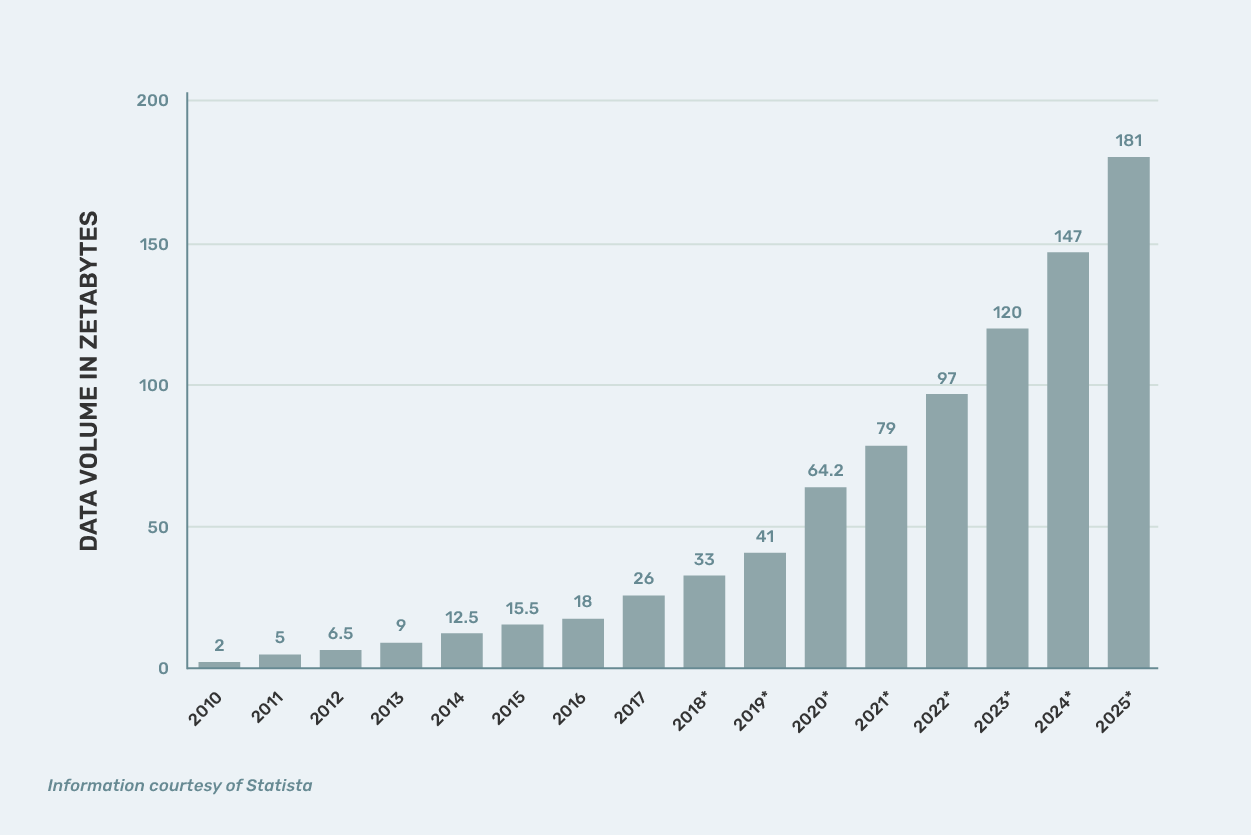
More Users = More Data
Out of the nearly 8 billion people in the world, 5.35 billion of them, or around 66% of the world’s population, have access to the internet. By Q3 of 2023, it was estimated that almost 96 percent of the global digital population used a mobile device to connect to the internet. Global users spend almost 60 percent of their online time browsing the web from their mobile phones. The most popular app activities on mobile were chatting and communicating, as well as listening to music and online banking activities.
New Data Types
In the litigation sphere, new types of data beyond the traditional email, word processing and spreadsheet platforms have emerged.
Some common types of emerging data include:
- Mobile data
- Messaging data
- Marketing data
- Medical data
- IoT data
- Collaboration app data (e.g. Slack and Teams)
These new forms of electronically stored information (ESI) often create new ediscovery challenges. But developing a foundational data strategy will give you the tools to navigate any data set, no matter how large it is or what it contains. In the next section, I will share strategic tips for managing legal data that I’ve learned from years of ediscovery consulting.
Part 2: Big Data in Litigation
A Brief History of Legal Data
How does all this large data fit into the historical timeline of litigation? The first “large” document case I was directly involved with was a coordinated action in Sacramento, CA in 1986. I maintained an index (no images) of 5 million pages loaded into the DOS (disk-based) version of Summation on a Compaq 386 computer with two 1.2 MB floppy drives and a 40 MB hard disk drive. The PC cost $7,999 and featured a 20 MHz Intel 80386 CPU, 1 MB RAM, and 16 KB ROM. (Today, you can buy a MacBook Air with 8 GB – or 8,000 MB – of RAM for $1,000.)
By the mid 90’s, I was working for the Texas Attorney General in their tobacco litigation. I ran a coding shop in 3 shifts with 35-50 coders per shift using a LAN with Gravity software. We eventually housed a database of 13 million pages, again no images.
The image below is of the Minnesota tobacco archives where the attorney general collected 28,455 boxes stacked in rows up to 12 high, 4 wide, 70 deep, containing 93 million pages of paper. It was the largest single records collection in the history of tobacco litigation.

In 2011, I began working with an iCONECT database here in New Orleans for the Plaintiffs in the BP oil spill case. We had 1 billion pages of emails, word processing documents, spreadsheets, proprietary data applications, and instrumentation reports. The documents were in a private cloud which was accessed by more than 100 outside law firms and their experts, representing more than 116,000 individual plaintiffs. At any given point in time, 300 reviewers from over 90 law firms representing various case teams as well as several state attorneys were accessing the database.
Today, there is a Relativity database in the January 6th insurrection cases with files for both the U.S. Attorney data and over half of the 1200+ defendants, all of which exceeds 10TB. It contains predominantly emails, texts, video and audio files taken from seized cell phones which were then produced to the defense.
6 Essential Data Strategies
So, what strategies can we use to handle all this data? And do any of the ones we used in 1986 still apply?
1. The Z Factor
The most important strategy is not technological at all. It is what Bruce Markowitz, the SVP at Evolver Legal Services, likes to call “the Z factor.” We all know about the X factor, the great unknown, but the Z factor is one which is often unarticulated.
In a nutshell, it’s the question I always ask my clients when we start a project. “What is it you want to do?” Bruce says, “What is the end result you need?” Take the answer to that question and build your workflow around it.
2. Map Your Data
I’ve said it over and over, many times. Get with the IT staff and generate a data map. In the old days it was easy… You simply asked where the warehouse with the boxes was. Now you need knowledgeable IT staff to show you the way. You’re Lewis and Clark, and they’re Sacajawea. You’re not going to get where you need to go without them.
Once you have a data map, you can decide:
- What data might potentially be relevant;
- Where that data is located;
- Who is in charge of managing that data; and
- How to make sure it is preserved.
3. Litigation Holds
This is not a one and done task. You need someone who knows how to craft and manage a comprehensive hold notification and follow up on it periodically.
4. Analytics
Not something we had in the paper days. The sooner you can use data analytics to quantify the key issues of potential litigation, the better. A good analytics assessment, even if just with a significant sampling of data, can be crucial in developing a case strategy.
The most basic ediscovery analytics tools are Email Threading and Near-Duplicate Identification. Some people like to consider foreign language detection in that list; I would also include simple data filtering by date/custodian.
More complex analytics includes machine learning tools such as Concept Clustering, Find Similar, Categorization, Key Word Expansion/Concept Searching and even Predictive Coding.
All of these tools help us better understand the data in ways that would normally involve extensive manual review.
Whatever your eventual list of analytic tasks, the purpose is to meet your data analysis goals quickly and easily. Ultimately, you need to search through large amounts of data to find potential evidence. Whether that is something as simple as finding privileged documents or more complex searches for responsive material, the first step is identify what you want to do, then select the analytic tool or tools to assist in that task.
5. Standardization
Again, not a factor in the early days of large data cases as we struggled to work with paper documents and early formats of electronic data, which each required their own OS or specialty database.
Now a key feature of ESI processing is to put all the data in a common format for review. However, agreeing on this format can be problematic, so remember that Rule 26(b)(1) of the Federal Rules of Civil Procedure requires parties to conduct a pre-trial meeting to agree on a proposed discovery plan which should include this component.
To make a strong case for favorable proportionality, parties must understand their data, build strong collaboration across business units, and utilize ediscovery software to enhance collaboration and streamline the process.
6. ESI Protocol
Although not required by Rule 26(b)(1), drafting an ESI protocol, or data exchange protocol, is encouraged by many observers, including the Sedona Conference and the EDRM. Having a specific agreement on data exchange makes standardization easier and more efficient.
There are a number of exemplar generic ESI protocols available including one by Craig Ball and guidelines from several US District Courts including the Northern District of California and the District of Maryland. Nextpoint also offers an ESI protocol checklist.
Keep in mind that a protocol should act as a roadmap for your case. Start it early and refer to it often. Your opponent may or may not accept it, but it will serve as a valuable guide for you and the court in working with your evidentiary documents.
Tools and Resources for Big Data in Litigation
Nextpoint takes a proactive approach to large data sets by using two of the tools I mention above, Mapping and Analytics, in their Early Data Assessment tool called Data Mining. Data Mining allows legal teams to sift through a mountain of electronic data to find potential evidence, thus reducing the data size and providing valuable insights which allow informed decisions for a more productive document review.
Nextpoint also has a sister organization called Nextpoint Law Group, a law firm that specializes in providing data-driven legal services to other firms and legal teams. If you’re not sure how to navigate a large data set, bringing in the experts is always a good idea. They can help you with ESI protocols, data filtering, analytics, and more.