DeNISTing in ediscovery is one of the many technical strategies utilized during the processing stage to eliminate irrelevant data from a document collection.
With the high volume of legal data seen in most litigation today, eliminating irrelevant files at the outset of a case is essential to maintaining a feasible workload for review. DeNISTing gets rid of all the extra noise from a computer, allowing you to focus only on the files touched and created by a human user. While the terminology may sound foreign, the concept is relatively simple.
You Practice Law. What Does This Have To Do With You?
Many legal professionals brush off technical processes like DeNISTing, deeming them a job for the IT team. But a well-rounded attorney should understand what’s happening with their legal data at each stage of the case to ensure the integrity of the evidence is maintained. This understanding also helps attorneys navigate the Meet and Confer, negotiate ESI protocols that will minimize discovery issues, and make strategic decisions about how to implement various technologies in their case, rather than fully relying on ediscovery professionals.
DeNISTing in Ediscovery: Get Rid of the Noise
If you’ve had your computer for a few years, you may have reached a point where apps are crashing, the screen is freezing, and you’re constantly hitting the restart button. When this happens, computers are usually in need of a deep cleaning of all the extra junk files they’ve accumulated over the years. These are the files that are created in the background when you download an app or run a program on your computer. They’re necessary for the operating system to run, but users never touch them, and often don’t even know they exist. So, you can download an app like CleanMyMac to scrub your hard drive of all the junk and let your computer start afresh.
Since users don’t create or interact with these files, it’s safe to conclude that they have no evidentiary value. DeNISTing ediscovery data does the same job as the cleaning apps, and a little more. It removes all the junk files as well as the core system files that computers use to operate on the back end. This way, when you’re searching through the contents of a custodian’s hard drive, you’re not lost in all the .exe and .dll files taking up space on the PC.
Why “DeNIST”?
NIST is an acronym for the National Institute of Standards and Technology, an agency of the U.S. Department of Commerce. NIST has a sub-project called the National Software Reference Library, which collects a master list of known, traceable computer applications. The DeNISTing process uses this list to identify the computer files known to be unimportant system files and remove them from the document collection.
How It Works: The Hash Value
The DeNIST feature uses something called an “MD5 Hash Value” to identify the documents that should be removed from the collection. The hash value of a file is like a digital fingerprint – every unique file will also have a unique hash value. This number allows processing systems to identify the unnecessary files from the NIST list as well as duplicate documents and more. The number is calculated using the MD5 algorithm, hence the name “MD5 Hash Value.”
DeNISTing Ediscovery Data in Nextpoint
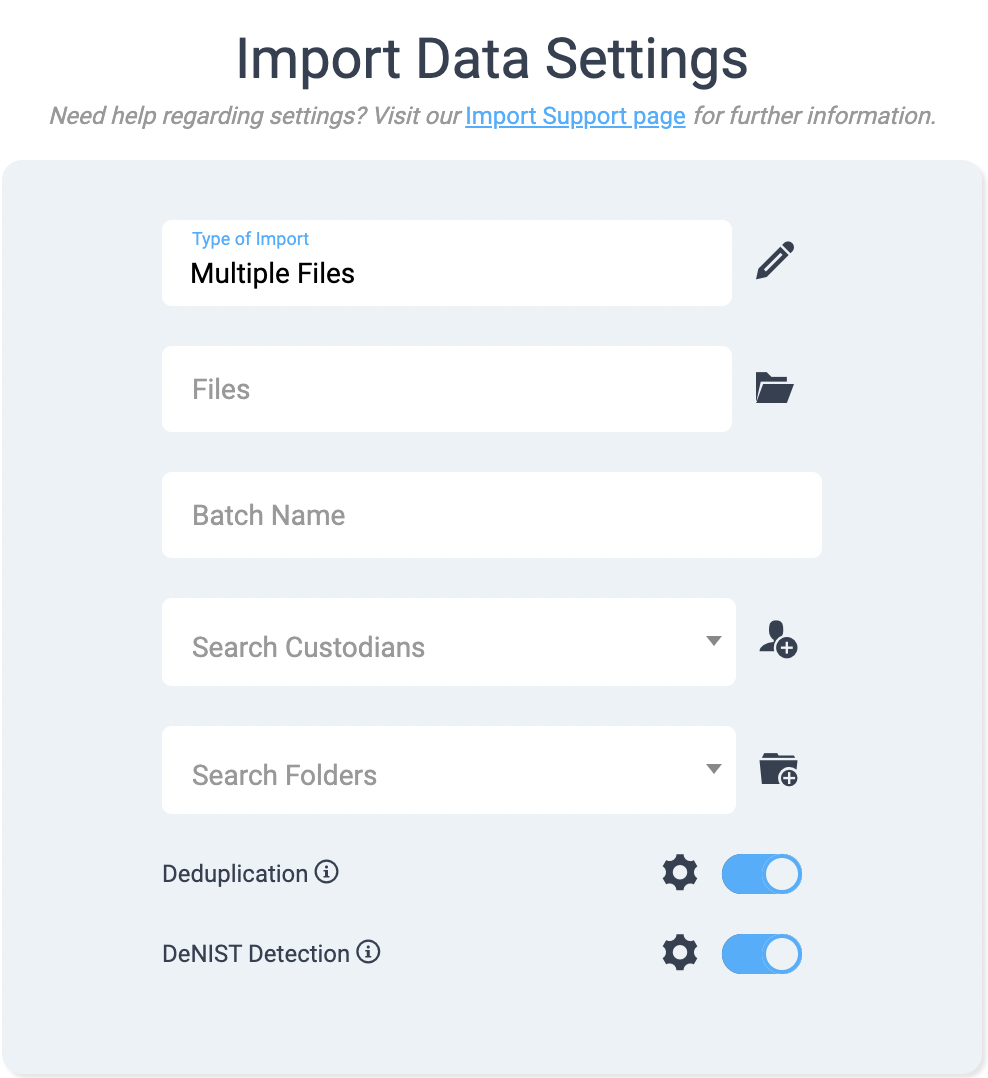
In Nextpoint, the DeNIST feature is applied at the import stage. It’s important to know whether you will be DeNISTing ediscovery data prior to import so that it doesn’t have to be re-processed later on. Simply toggle on “DeNIST Detection” and all files from the NIST list will be identified.
Users have two options for applying the DeNIST feature: filtering and tagging. Filtering completely removes files from imported batches, so your database won’t be polluted with these extra files. Tagging applies a special “NIST” tag to all the matching files. They will be imported into the database as usual, and the tag will allow you to easily identify files from the NIST list when managing your data.
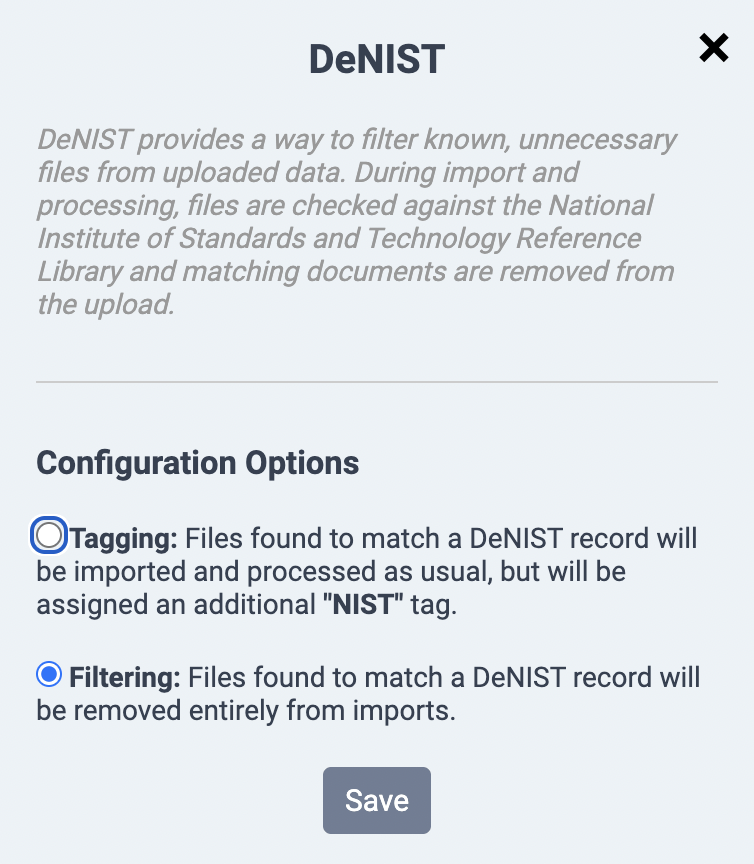
We recommend using the filtering method because it’s highly unlikely that any DeNISTed files will be relevant to your case, and removing them will give you a cleaner database that is easier to organize. There may be limited scenarios in which these files have evidentiary value; for example, you may need to demonstrate an individual’s possession and usage of a certain software application. However, these situations are atypical, and most ediscovery will be better served by fully removing the files from the NIST list.
Don’t Hesitate to Use the NIST List
We have found some lawyers are reticent about deleting files without knowing what is in them. They should know that the NIST list is continually updated and vetted. The National Institute of Standards and Technology does not take its task lightly, and the process is routine and authenticated. If you’re still concerned about removing these files, utilize the tagging feature so that they can be easily identified and organized in the database.
Of course, remember that the NIST list does not contain every single junk or system file in the known Universe. It’s just one step in a larger process to limit your collection.
Processing Strategies for Easier Ediscovery
With the recent explosion of legal data volumes, the processing stage has come to the forefront of ediscovery conversations. Early Data Assessment has gained traction as a method for reducing and understanding data at the initial stages of a case in order to guide case strategy. (We recently released groundbreaking new technology for this process – check out Data Mining.) An effective processing workflow can set you up for success in the rest of discovery.
DeNISTing is just one technique you can utilize to cull down and organize data at the processing stage. Other steps Nextpoint performs on import include:
- Deduplication – All duplicate files are removed from the dataset, identified through their unique hash value.
- Near Deduplication – This process identifies and removes files that are near duplicates, like a Word Document that was printed to a PDF file – different file types with the same content.
- Email Threading – Email threading links all the emails from a single conversation together so that they can be reviewed consistently as a unit.
★ The Solution to Big Data is Here
Nextpoint’s new Data Mining software is here to revolutionize the way you manage ediscovery data. Data Mining gives users the power to reduce and analyze massive data loads at lightning speed early on in a case. When you get to discovery, you’ll hone in on the data that really matters, armed with constructive insights to guide your review strategy.
Schedule a free consultation with our team to see Data Mining firsthand and learn how Early Data Assessment tactics can simplify and optimize your ediscovery process. Click the button below to learn more about Data Mining and find a few minutes to chat.